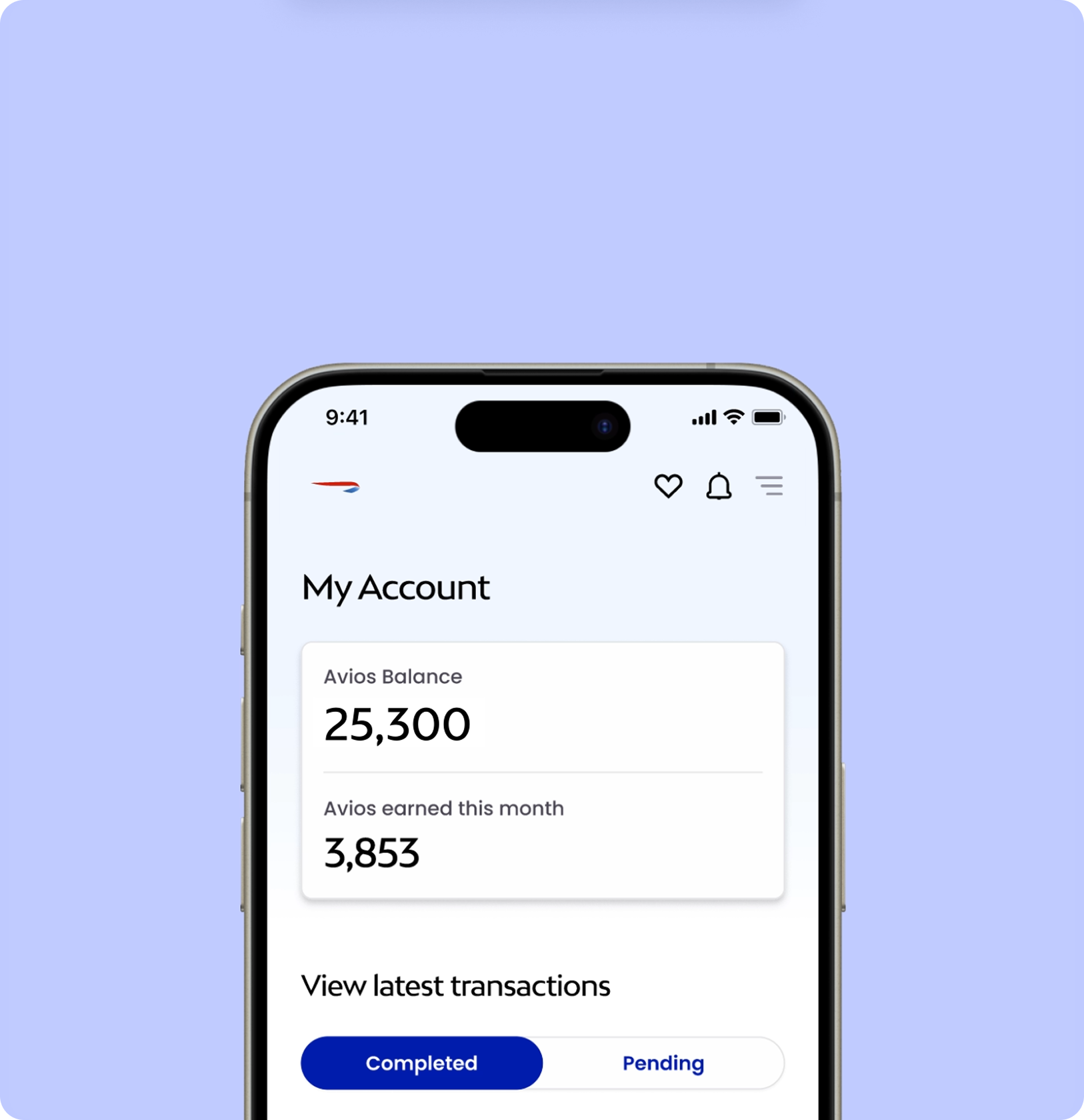
Move Avios between airline programmes
You can now transfer Avios between selected airline partners.
Avios is a global reward currency you can spend on flights, hotels, car hire and more. Start collecting now with thousands of retailers and make your next getaway your best yet.

###### Collect Avios with our [**2000+** partners](/en-GB/collect-avios/shopping/retailers/#browse-all "Browse all retailers"). Explore our featured partners. Select a logo to shop and collect Avios. BA logo, Amex logo, Uber logo, Nectar, Avis - Logo Banner, Currys logo, PizzaExpress logo, HelloFresh Logo
Spend Avios on flights, car hire, hotels, experiences or even wine. There’s something rewarding for everyone.
Ways to spend AviosAn example of how to spend your Avios: London to Amsterdam Reward Flight Saver - One way for 10,000 Avios + £1
An example of how to spend your Avios: London to Amsterdam Reward Flight Saver - One way for 10,000 Avios + £1
Spend Avios on flights, car hire, hotels, experiences or even wine. There’s something rewarding for everyone.
Ways to spend AviosYou can now transfer Avios between selected airline partners.


Curious about how Avios can help you save on you next trip? We have created a quick guide to show you how to get the most out of our loyalty programme
Find out more
Can you really use Avios to go on holiday anywhere in the world? It might sound too good to be true, but not only is it possible, it’s easier than you think.
Find out moreCurious to know what Avios can do for you? Check out our guides to find out how Avios can help power your next adventure.
Join a programme and start collecting Avios today.